

In the life science industry, Artificial Intelligence (AI) and Machine Learning (ML) validation have been the buzzwords of the past year.
Every major company in the industry wants to take advantage of these powerful analytical systems to optimize its processes. Unfortunately, this requires a straightforward, user-friendly and reliable validation framework when AI/ML-based systems are used or when an AI/ML-based product is introduced to the market.
Do you want to know more about the difference between Artificial Intelligence and Machine Learning? Do you need insight into the right validation strategy for your AI- or ML-based systems and products?
In this blog post, we’ll share both and discuss:
- What exactly is the difference between artificial intelligence and machine learning?
- What are the current proposed strategies for the validation of AI/ML-based tools and products?
- Examples of different types of Artificial intelligence and how they affect your validation strategy.
Curious about the answers? Be sure to read on!
What is the difference between artificial intelligence and machine learning
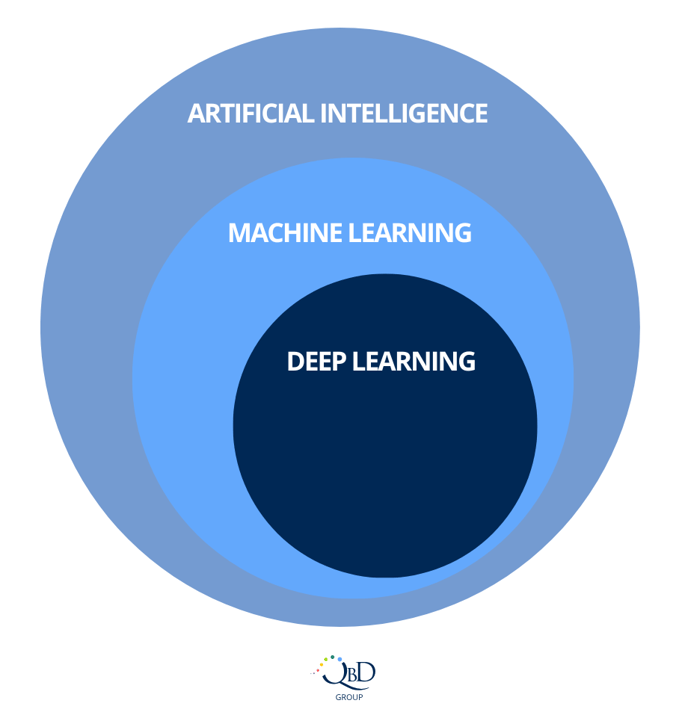
Figure 1 – A visual representation of how Artificial Intelligence, Machine Learning, and Deep Learning relate to each other
What is artificial intelligence?
Artificial Intelligence is defined as any technique that enables machines to mimic human intelligence. It enables machines to “think like humans”. Using these tools, it is possible to improve the efficiency of various decision-making processes but also to further drive innovation within your organization. They enable companies to unlock new value in data that is often captured today but rarely used to its full potential.
What is machine learning?
Machine learning goes a step further. It is a subset of AI that enables machines to improve autonomously through learning. This means that systems based on ML technology will improve incrementally while performing the tasks they were designed to execute. Who would have thought that even machines would start learning on the job?
AI and machine learning validation requirements
For both technologies, several difficulties arise when we begin to look at the validation requirements. Classically, validated systems are set in stone from the moment they are released. Validation is usually only re-evaluated when major updates are made to the system. Fixed algorithms ensure that every input generates the same output every time.
AI/ML-based systems are more of a special case because of the training, retraining and self-learning aspects of the software. To date, it is not yet possible to reverse engineer the thought process of AI or ML software, which makes it difficult to fully understand the software.
In practice, we call these systems black boxes. Their decision-making process is difficult to fully break down into testable pieces and when we look at ML-based systems, the process changes every time the system learns by performing the tasks it was put into service for. It can generate different outputs based on the training of the system.
Different AI types
To fully understand where the difficulties for AI validation and Machine Learning validation lie, we can divide all systems into 3 main categories according to Drug Safety – Validating intelligent automation systems in pharmacovigilance: Insights from good manufacturing practices.
1. Rule-based static systems
The first category is rule-based static systems. This is by far the largest group, as most systems currently in use at life science companies fall into this category. Automation in these systems is achieved through static rules and fixed algorithms. The validation framework for these types of systems today exists in guidelines and regulations such as GAMP5®, 21 CFR part 11, Eudralex volume 4 annex 11, and others.
2. AI-based static systems
The second category is AI-based static systems. These systems use artificial intelligence but are not self-learning. Training and learning take place before release and can be repeated with each update. Validation of these types of applications can usually be done according to current best practices and guidelines, but the AI component of these systems requires additional deliverables that we will discuss later in this blog.
The non-AI functions of these systems require no additional validation effort beyond the usual good practices outlined in, for example, GAMP®5. The well-known V-model can be used with either a waterfall oran agile development approach and the deliverables consist of user requirements, functional, design and/or configuration specifications, installation tests, functional tests and user acceptance tests, accompanied by a validation plan and summary report.
During this validation effort of the non-AI functions, some additional concerns should be considered when documenting and testing the AI component of the system. As with the non-AI portion, the AI component of the system must be validated. While the V-model deliverablesare a good start, additional information or testing efforts must be documented to adequately cover the AI model during validation.
Important aspects to keep in mind for the concept phase of the system life cycle primarily concern the data selection used for both training and testing of the system. Since this will have a major impact on the outcome of the validation, it must be done with due care, knowledge and expertise.
During the project phase of the system life cycle, the AI model should be described in model requirements and specifications. The design and training should be documented and conducted with the pre-selected set of training data and the result of testing the model based on the set of test data, the model requirements and specifications should also be documented.
During the operation phase of the system, the production/life cycle data set should be monitored and continually reviewed to determine if changes in this data set may require an adjustment to the training and testing data set and trigger any retraining effort.
3. AI-based dynamic systems
The third category is AI-based dynamic systems. Machine learning-based applications fall into this category. These types of systems change during the operational phase because of the machine learning aspect. The output of the system given a certain input might be different over time because the system learns.
Validation challenges are greatest in this category. The FDA proposal for an AI validation life cycle provides a first glimpse of where the focus should be to ensure that these systems are validated and maintained in a controlled state. Clear and practical regulations for this type of validation do not yet exist.
Validation Principles for AI validation and Machine Learning validation
Now that we know what different types of AI-based systems exist, the ISPE AI validation groups from Germany, Austria, and Switzerland have made a first proposal for AI validation strategies based on the autonomy and control design of the system. Using a few examples, we will explain how the autonomy and control design of a system defines the required validation effort.
Autonomy of a system
To understand how the maturity of a system determines the validation effort required, we will first look at the two components that determine its maturity. The first parameter is the autonomy of a system. This autonomy can range from the use of fixed algorithms (no AI/ML component) to a fully automated, independent and self-learning system.
The greater the ability to perform updates automatically, the greater the validation effort required to ensure that the system performs and continues to perform its tasks as intended throughout the system’s life cycle, as the system becomes more decision-maker of (automated) updates.
Control design
The second parameter is the control design. This control design can range from a system used in parallel with an existing validated process/system to an automatically operating system that controls itself. The more controls that monitor product quality and patient safety are given to the system, the greater the validation effort.
Dividing both aspects into 5 phases creates a grid that guides the AI validation effort based on the risk associated with the system. This grid gives us 6 categories for AI validation, increasing in risk and as such in control measures and deliverables.
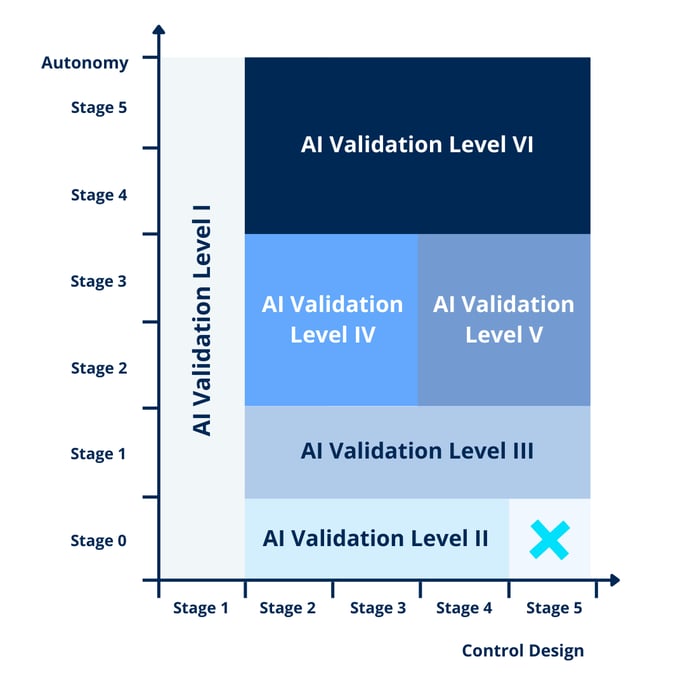
Figure 2 – Grid guiding AI validation effort (Source)
AI validation category I & II
The 2 lowest categories consist of:
- Category I: systems that do not require validation given they exist in parallel to a separate validated system
- Category II: systems that use fixed algorithms
Category II systems can be validated against current best practices. Examples can be found in almost every life science company in systems that automate production or QMS processes.
AI validation category III
From this category onward, all systems include some form of AI. Category III systems are used in a locked state and retraining of the AI model is done through periodic updates with training and testing datasets.
An example is image recognition systems that recognize different types of bacteria based on images of cell cultures. This system is trained during the development stages to recognize different types of bacteria based on labeled bacteria images.
For the validation of this system, we need to extend our validation of good practices to the AI model, in addition to the conventional validation of automated systems. Since the training and testing data used during development will determine the output of the system, the focus of the validation of the AI model for these systems should be on the data.
Mislabeled training or test data, data bias, or corruption can greatly affect the outcome of our system. Therefore, risk analysis, data integrity assessment, and data labeling procedures should ensure the quality of the data used.
In addition, during testing, it must be verified that the selected AI model is appropriate for the use case and that the trained model produces the expected results based on the input data. After release, predetermined conditions and system monitoring should trigger retraining based on the model’s performance.
AI validation categories IV & V
The difference in the AI validation approach for Category IV and V systems lies in the retraining. Systems of these categories make their own decisions, but some form of human control remains, either by seeking approval for each decision or by allowing the decision to be revised.
Systems of AI validation category IV are those that leave control of retraining and updates to a human, either through manual retraining or an approval step after automatic retraining. For these systems, it is important during validation to increase the monitoring of the system and the AI model during operations and to compare the outcomes with the KPIs for quality during operations.
For systems in AI validation category V, retraining and updates are done entirely by the system itself; human monitoring remains only in the monitoring step for decisions made by the system. To ensure that the system still produces the results expected based on the input data, periodic retests with a predefined set of test data should be performed during the operation phase to check the system and ensure that the results still match what is expected.
An example of these systems is predictive maintenance systems. These systems provide decisions about when and what equipment needs maintenance to avoid long-term failures or high repair costs. Depending on the system in question and the control it has over updates and retraining, the system would fall into one of these two categories. Systems learn from the input data they receive by comparing it to data generated during previous outages or maintenance to predict when a system needs to be looked at.
AI validation category VI
The systems with the greatest risk are those without any human control over the outcome or training aspect of the system. Currently, there are no best practices available to validate these types of systems, given the ever-changing nature and lack of human control related to this era of AI/ML systems.
Conclusion
Although Artificial Intelligence (AI) and Machine Learning (ML) are buzzwords in the life sciences industry, current best practices already provide a good framework for the vast majority of automated system validation of AI-based systems. By extending the system with a focus on the AI model, we can provide fully validated systems for use in the life sciences industry.
This allows us to take advantage of these powerful analytical systems to optimize processes and help patients.**Do not hesitate to contact us**to see how we can help you implement AI-based systems or provide a framework to bring AI-based products onto the market.

About the Author

Project Manager at QbD Group
Pieter is a Project Manager at QbD Group, coordinating multi-disciplinary teams to deliver quality and regulatory consulting projects.


